Learning Effective Spatial–Temporal Features for sEMG Armband-Based Gesture Recognition
1. どんなもの?
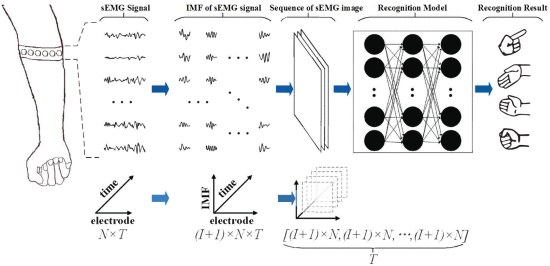
時間的に非定常信号であるsEMGを空間-時間特徴に基づく、ジェスチャー認識法(STF-GR)の提案。非定常多チャンネルのsEMGを分解し、定常副信号に合同変換したのち、空間的独立性と時間的定常性を生み出す。その後負の対数尤度ベースのコスト関数を用いて,最終的なジェスチャーの判定する。STF-GRはsEMGアームバンドのために設計されたもの。
2. 先行研究と比べてどこがすごいの?
● sEMGの本質的な空間的・時間的特徴を学習する新しいジェスチャー認識フレームワークであるという点 ● sEMG信号は、時間的には非定常性と非線形性があり、空間的には隣接する複数の筋肉に関連しているため、IoTシステムにおけるsEMGには限界があったがSTF-GRはsEMG信号の本質的な特性を考慮した、sEMGベースのジェスチャー認識のための新しいアイディアであるという点。
3. 技術や手法の"キモ"はどこにある?
● EMDを改良したMEMD*ベースのマルチチャンネルsEMG信号解析
マルチチャンネルの正体電気信号の2次元のsEMGデータを3次元に変換する。
多チャンネル信号の極値,モーションパターンを直接定義することができないため、多チャンネル信号を異なる方向に沿ってn次元空間に投影する。
● CRNNベースの特徴学習戦略
空間的特徴を畳み込み層で抽出し,抽出した空間的特徴のシーケンスをリカレント層に与えて時間的特徴を抽出する.
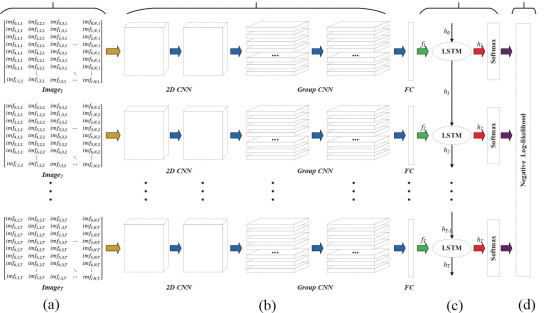
● ジェスチャー認識プロセス
オンライン予測モデルの構築には,CRNNの出力を受け取るために,1つの負の対数尤度層を使用する
4. どうやって有効だと検証した?
● CapgMyo,NinaPro,BandMyoの3つのデータセットで実験を行い、手法ではいくつかの特徴量を元にしたRFとSVMを使う。
5. 議論はあるか?
● 増分学習、転移学習、メタ学習などの高度な学習理論を利用して操作位置依存性やユーザー依存性を抽出する。 ● 認識率の上昇 ● 特定の被験者で学習したモデルは他の被験者のジェスチャー認識が困難